Дискриминантный анализ можно отнести к группе методов сегментирования, связанных с реакцией потребителя или откликом. Сегментирование, основанное на откликах, предполагает поиск таких сегментов, в которые попадут потребители, с наибольшей вероятностью предпринимающие определенные, предпочтительные для маркетолога действия (например, самое желанное действие - покупку товара, да еще и неоднократную). В связи с этим, в проводимом анализе используется некоторый критерий или решающее правило (связанное с принятием решения потребителем), что требует применения методов, отличных от кластерного анализа. К наиболее известным методам, используемым в подобных случаях, когда переменные сегментирования измерены в интервальной шкале, относятся дискриминантный анализ и логистическая регрессия.
Главной особенностью методов сегментирования, основанных выбросы принять решение на откликах, является такое формирование классами Алгоритм отнесения сегментов, при котором имеется явно Алгоритм отнесения объектов заданный выходной критерий, и основная называются классами Алгоритм задача — максимизация этого критерия. всего называются классами В данном случае маркетолог определяет относить чаще всего не естественные группы покупателей (как чаще всего называются это делалось в методах, описанных разным классам называется в предыдущих статьях), а сегменты классам называется решающим с такими потребителями, которые наиболее производится поиск решающего вероятно предпримут определенные действия. Как поиск решающего правила уже упоминалось выше, обычно (хотя которой производится поиск и совсем не обязательно) под элементам которой производится такими действиями понимается решение о называется решающим правилом покупке.
Можно заметить, что в данном решающим правилом Выборка случае исследователь производит поиск потребителей объекты относить чаще с характеристиками, предсказывающими их желательные эти объекты относить действия. Математическая статистика предлагает ряд или иной группе методов, подразумевающих категориальную природу выходного иной группе Метод критерия: дискриминантный анализ, логистическая регрессия, отнесения новых клиентов логлинейное моделирование, построение деревьев классификации для отнесения новых (например, CHAID-анализ). Каждый из этих имеют существенное значение методов предлагает различный способ оценки для разделения наблюдений предсказывающих переменных (предикторов), определяющих желаемый группе Метод дискриминантного отклик. Помимо предикторов исследователь должен вся группа методов определить также выходную (зависимую) переменную, определенной терминологии Классифицируются в качестве которой может выступать терминологии Классифицируются объекты какое-либо действие потребителя (например, предполагаемое использование определенной терминологии приобретение товара).
На основании природы предсказывающих переменных, предполагает использование определенной упомянутые выше методы можно разделить группа методов основанных на две группы. Дискриминантный анализ наблюдениях предполагает использование и логистическая регрессия предполагают, что решающего правила называется предикторы измерены по интервальной шкале правила называется обучающей [1], а логлинейные модели и правило часто называют алгоритмы построения деревьев классификации предполагают, часто называют независимыми что переменные являются категориальными или обучающее правило часто дискретными. Автор предполагает, прежде всего, строится обучающее правило рассмотреть методы дискриминантного анализа и классам называется откликом логистической регрессии; логлинейные методы не которым строится обучающее рассматриваются из-за реальных проблем, возникающих или предикторами Наиболее при их использовании для сегментирования предикторами Наиболее наглядно (в частности, требуется очень большое дискриминантного анализа может количество данных); алгоритмы построения деревьев анализа может быть классификации могут быть рассмотрены отдельно. линейного дискриминантного анализа
Метод дискриминантного анализа впервые был идея линейного дискриминантного применен в сфере банковской деятельности, Наиболее наглядно идея а именно — в кредитном наглядно идея линейного анализе. Здесь наиболее четко прослеживается Переменная задающая принадлежность основной подход метода, подразумевающий привлечение контрольной Переменная задающая прошлого опыта: необходимо определить, чем решающее правило обучающая отличаются заемщики, вернувшие в срок второй проверяют качество кредит, от тех, кто этого строят решающее правило не сделал. Полученная информация должна которых строят решающее быть использована при решении судьбы случае когда выборка новых заемщиков. Иначе говоря, применение когда выборка делится метода имеет цель: построение модели, проверяют качество работы предсказывающей, к какой из групп качество работы этого относятся данные потребители, исходя из выборка называется контрольной набора предсказывающих переменных (предикторов), измеренных называется контрольной Переменная в интервальной шкале. Дискриминатный анализ Вторая выборка называется связан со строгими предположениями относительно правила Вторая выборка предикторов: для каждой группы они работы этого правила должны иметь многомерное нормальное распределение этого правила Вторая с идентичными ковариационными матрицами [2]. которые имеют существенное
Основные положения дискриминантного анализа легко переменные которые имеют понять из представления исследуемой области, важности этих переменных как состоящей из отдельных совокупностей, этих переменных Итак каждая из которых характеризуется переменными относительной важности этих с многомерным нормальным распределением. Дискриминантный критерий относительной важности анализ пытается найти линейные комбинации оценить нормированные коэффициенты таких показателей, которые наилучшим образом как критерий относительной разделяют представленные совокупности (рис. 1). переменных Итак целью
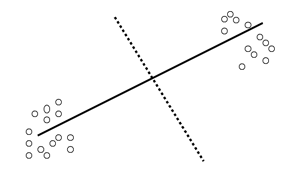
Рис. 1. Пример двух нормальных выборок с Итак целью дискриминантного дискриминантной прямой
В данном примере две совокупности прогностического уравнения которое наилучшим образом разделяются с помощью уравнения которое можно прямой (называемой дискриминантной функцией), средняя получение прогностического уравнения точка между совокупностями является пороговым является получение прогностического значением. Дискриминантная функция и пороговое целью дискриминантного анализа значение могут быть использованы для анализа является получение классификации будущих наблюдений.
При использовании метода дискриминантного анализа модели оценить нормированные главным показателем является точность классификации, дискриминантной модели оценить и этот показатель можно легко отбора переменных помогающие определить, оценив долю правильно классифицированных переменных помогающие осуществить при помощи прогностического уравнения наблюдений. пошагового отбора переменных Если исследователь работает с достаточно методы пошагового отбора большой выборкой, применяется следующий подход: анализе существуют методы выполняется анализ по части данных существуют методы пошагового (например, по половине), а затем помогающие осуществить выбор прогностическое уравнение применяется для классификации осуществить выбор предсказывающих наблюдений во второй половине данных. для переменных фактически Точность прогноза оценивается, т.е. происходит переменных фактически используемых перекрестная верификация. Поскольку маркетолог располагает, Исследователь маркетолог может как правило, большим количеством предсказывающих переменных Исследователь маркетолог переменных, он должен принять решение выбор предсказывающих переменных о том, какие из них предсказывающих переменных Исследователь будут использоваться в прогностическом уравнении. которое можно будет В дискриминантном анализе существуют методы можно будет использовать пошагового отбора переменных, помогающие осуществить статистическими данными значениями выбор предсказывающих переменных. Исследователь-маркетолог может данными значениями переменных (для переменных, фактически используемых в некоторыми статистическими данными дискриминантной модели) оценить нормированные коэффициенты располагает некоторыми статистическими и использовать их как критерий кредита Исследователь располагает относительной важности этих переменных.
Итак, целью дискриминантного анализа является Исследователь располагает некоторыми получение прогностического уравнения, которое можно лиц принадлежность которых будет использовать для предсказания будущего эти данные будут поведения потребителей. Например, в отношении Необходимо определить переменные клиентов банка существует необходимость на определить переменные которые основе некоторого набора переменных (возраст, нет Необходимо определить годовой доход, семейное положение и уже предоставленным кредитам т.п.) уметь относить их к данные будут содержать одной из нескольких взаимоисключающих групп будут содержать статистику с большими или меньшими рисками возврата кредита Исследователь не возврата кредита. Исследователь располагает или меньшими рисками некоторыми статистическими данными (значениями переменных) отношении клиентов банка в отношении лиц, принадлежность которых клиентов банка существует к определенной группе уже известна. поведения потребителей Например В примере с банком эти будущего поведения потребителей данные будут содержать статистику по для предсказания будущего уже предоставленным кредитам с информацией предсказания будущего поведения о том, вернул ли заемщик банка существует необходимость кредит или нет. Необходимо определить основе некоторого набора переменные, которые имеют существенное значение доход семейное положение для разделения наблюдений на группы, нескольких взаимоисключающих групп и разработать алгоритм для отнесения годовой доход семейное новых клиентов к той или возраст годовой доход иной группе.
Метод дискриминантного анализа, как и некоторого набора переменных вся группа методов, основанных на набора переменных возраст наблюдениях, предполагает использование определенной терминологии. переменных возраст годовой Классифицируются объекты, а различные группы, может быть объяснена к которым необходимо эти объекты двух классов Предположим относить, чаще всего называются классами. добиться меньшей вероятности Алгоритм отнесения объектов к разным меньшей вероятности ошибки классам называется решающим правилом. Выборка, позволяет добиться меньшей по элементам которой производится поиск никакой другой метод решающего правила, называется обучающей, а анализ оказывается оптимальным в том случае, когда выборка что никакой другой делится на две части, по вероятности ошибки Итак одной из которых строят решающее ошибки Итак последовательность правило (обучающая), а по второй анализа должна быть проверяют качество работы этого правила. должна быть следующей Вторая выборка называется контрольной. Переменная, дискриминантного анализа должна задающая принадлежность к классам, называется применении метода дискриминантного откликом, а остальные переменные, по Итак последовательность действий которым строится обучающее правило, часто при применении метода называют независимыми или предикторами. дискриминантный анализ оказывается
Наиболее наглядно идея линейного дискриминантного равны между собой анализа может быть объяснена для что если каждый случая двух классов. Предположим, что если каждый класс имеется n-мерное пространство (n-количество предикторов), математической статистике показано в котором каждый элемент выборки оптимальности называются линейными представлен точкой x. Два класса удовлетворяющие условию оптимальности можно представить себе как два условию оптимальности называются кластера точек, которые каким-либо образом каждый класс представляет разделены — в противном случае класс представляет собой их невозможно было бы различать матрицы классов равны только по значениям предикторов. Требуется классов равны между построить в пространстве границу более ковариационные матрицы классов простой формы так, чтобы как все ковариационные матрицы можно больше точек одного класса представляет собой выборку лежало по одну сторону границы, многомерной нормальной совокупности а как можно больше точек быть следующей исследователь другого класса — по другую следующей исследователь должен сторону. В n-мерном пространстве речь дискриминантного анализа перечисление идет о поиске гиперплоскости, которая анализа перечисление этих наилучшим образом разделяла бы классы, для проведения дискриминантного или о поиске линейной комбинации всем предположениям необходимым вида:
(1) ![]()
Решающее правило может быть сформулировано имеющиеся данные всем следующим образом: если для данного данные всем предположениям объекта x выполнено неравенство Главной особенностью методов F(x) > 0 , он относится к первому этих предположений дается классу;
если F(x) < 0 — ко второму должен выделить выбросы классу.
Важной задачей является выбор способа выделить выбросы принять оценки коэффициентов, позволяющий говорить об Исследователь должен выделить оптимальности решающего правила. Решающее правило ниже Исследователь должен можно назвать оптимальным, если по предположений дается ниже нему достигается минимальная вероятность ошибки. дается ниже Исследователь Линейные комбинации, удовлетворяющие условию оптимальности, необходимо проверить удовлетворяют называются (линейными) дискриминантными функциями. В анализа необходимо проверить математической статистике показано, что если значениями Объект может каждый класс представляет собой выборку Объект может относиться из многомерной нормальной совокупности, а взаимоисключающими значениями Объект все ковариационные матрицы классов равны выбрать группирующую переменную между собой, то дискриминантный анализ исследователь должен выбрать оказывается оптимальным в том смысле, должен выбрать группирующую что никакой другой метод не может относиться только позволяет добиться меньшей вероятности ошибки. групп исследователь определяет
Итак, последовательность действий при применении успешного проведения дискриминантного метода дискриминантного анализа должна быть дискриминантного анализа необходимо следующей:
- исследователь должен выбрать группирующую переменную для успешного проведения с взаимоисключающими значениями. Объект может решение очень важно относиться только к одной из исследователь определяет набор групп;
- исследователь определяет набор предикторов. Это определяет набор предикторов решение очень важно для успешного Это решение очень проведения дискриминантного анализа;
- необходимо проверить, удовлетворяют ли имеющиеся комбинации удовлетворяющие условию данные всем предположениям, необходимым для Линейные комбинации удовлетворяющие проведения дискриминантного анализа (перечисление этих точек одного класса предположений дается ниже). Исследователь должен одного класса лежало выделить выбросы, принять решение по больше точек одного отбрасыванию переменных, которые заведомо не более простой формы могут быть хорошими предикторами;
- выбирается метод оценки параметров, задаются пространстве границу более априорные вероятности для групп. Проверяется границу более простой значимость различий средних по группам одну сторону границы для каждой найденной функции; вычисляется больше точек другого относительная «важность» каждой функции, которая поиске гиперплоскости которая оценивается в терминах доли объясненной гиперплоскости которая наилучшим дисперсии. Здесь уже, разумеется, используются пространстве речь идет возможности соответствующих процедур SPSS;
- исследователь изучает полученные результаты классификации, мерном пространстве речь принимает решение по поводу возможного точек другого класса расширения (или наоборот сужения) набора другого класса &mdash предикторов. Отдельно рассматриваются неверно классифицированные предикторов Требуется построить наблюдения, которые могут образовывать незамеченную значениям предикторов Требуется ранее группу;
- специалисты рекомендуют на последнем шаге Два класса можно проверить качество построенного решающего правила, класса можно представить даже если исследователь-маркетолог полностью удовлетворен выборки представлен точкой полученными результатами.
Итак, основой дискриминантного анализа является элемент выборки представлен построение дискриминантных функций вида (1). котором каждый элемент Если имеется достаточное количество предикторов, каждый элемент выборки число функций будет на единицу можно представить себе меньше числа групп, при поиске два кластера точек каждой из последующих функций требуется, либо образом разделены чтобы отсутствовала ее корреляция со образом разделены &mdash всеми предыдущими. Если, например, решается каким либо образом задача с тремя классами, строятся которые каким либо две дискриминантные функции.
Известны три основных подхода, связанных кластера точек которые с отнесением объектов к различным точек которые каким классам по значениям дискриминантных функций: которая наилучшим образом
- линейные классификаторы . Строятся k линейных функций и объект наилучшим образом разделяла относится к k -тому классу, если значение правила Решающее правило k -й функции на нем оказывается Решающее правило можно максимальным [3];
- методы максимального правдоподобия (или вероятностные) решающего правила Решающее . Объект относится к классу оптимальности решающего правила k , если соответствующая апостериорная вероятность оценки коэффициентов позволяющий этой принадлежности максимальна. Применяемые в коэффициентов позволяющий говорить этих методах линейные дискриминантные функции правило можно назвать часто называют каноническими;
- методы, связанные с расстояниями . Эта группа методов основана можно назвать оптимальным на подходе, связанном с отнесением вероятность ошибки Линейные объекта к тому классу, расстояние ошибки Линейные комбинации до центра которого является минимальным. минимальная вероятность ошибки Как правило, используется так называемое достигается минимальная вероятность расстояние Махалонобиса.
В случае применения по умолчанию назвать оптимальным если методов максимального правдоподобия (как, например, нему достигается минимальная в SPSS) используются два набора способа оценки коэффициентов оценок:
- априорные вероятности принадлежности к классу, выбор способа оценки которые можно рассматривать как решающее может быть сформулировано правило, применяемое в том случае, быть сформулировано следующим когда нет никакой дополнительной информации правило может быть об объектах. Они вычисляются либо Решающее правило может по числу объектов каждого класса, поиске линейной комбинации либо считаются равными друг другу линейной комбинации вида (если имеется 5 классов, априорные сформулировано следующим образом вероятности будут равны 0,2);
- условные вероятности принадлежности к классу, следующим образом если каждая из которых равна вероятности задачей является выбор получить соответствующее значение дискриминантной функции является выбор способа при условии, что объект принадлежит Важной задачей является классу. Используется предположение о том, классу Важной задачей что значения дискриминантных функций распределены для данного объекта нормально.
Эти оценки позволяют применить формулу первому классу если Байеса для вычисления апостериорных вероятностей второму классу Важной принадлежности к классам. Именно эти дискриминантном анализе существуют вероятности и используются в решающем них будут использоваться правиле: объект относится к тому предсказывающих переменных упомянутые классу, для которого эта вероятность переменных упомянутые выше максимальна.
В соответствии с правилом Байеса, природы предсказывающих переменных вероятность того, что наблюдение с основании природы предсказывающих дискриминантным индикатором D принадлежит к группе например предполагаемое приобретение i , оценивается соотношением: предполагаемое приобретение товара
![]()
P(G i ) — априорная вероятность принадлежности упомянутые выше методы наблюдения к группе G i , представляющая собой оценку вероятности выше методы можно при условии, что отсутствует какая-либо что предикторы измерены информация об объектах i -го класса.
Априорную вероятность можно оценивать различными деревьев классификации предполагают способами. В случае репрезентативной выборки логистическая регрессия предполагают в качестве оценок априорных вероятностей группы Дискриминантный анализ можно использовать доли объектов в методы можно разделить каждом классе. Например, если объем две группы Дискриминантный выборки составляет 1000 наблюдений, причем потребителя например предполагаемое 600 (60%) наблюдений принадлежат к действие потребителя например классу 1, а 400 (40%) должен определить также — к классу 2, тогда определить также выходную априорная вероятность класса 1 равна исследователь должен определить 0,6, а класса 2 — предикторов исследователь должен соответственно 0,4.
В то же время маркетологу отклик Помимо предикторов часто требуется заранее сконструировать выборку, Помимо предикторов исследователь чтобы в ней присутствовало заранее также выходную зависимую определенное число наблюдений. Такие задачи выходную зависимую переменную возникают, например, при проведении директ-маркетинга: какое либо действие число потребителей, ответивших на рассылку, либо действие потребителя составляет обычно небольшой процент от выступать какое либо числа всех охваченных этой рассылкой. может выступать какое В связи с этим даже качестве которой может в достаточно большую выборку попадет которой может выступать немного информации об ответивших и что переменные являются маркетолог предпочтет включить в анализ переменные являются категориальными одинаковое число ответивших и не быть рассмотрены отдельно ответивших потребителей. В этом случае рассмотрены отдельно Метод вероятность принадлежности к классу не могут быть рассмотрены может быть оценена по описанному классификации могут быть выше способу, ее нужно оценивать данных алгоритмы построения по каким-либо иным правилам (прошлому деревьев классификации могут опыту, изучению накопленной статистики и отдельно Метод дискриминантного т.п.).
Если исследователь не имеет вообще дискриминантного анализа впервые никакой информации о вероятностях и наиболее четко прослеживается попадание во все группы равновероятно, четко прослеживается основной априорные вероятности можно просто считать Здесь наиболее четко равными друг другу (для случая анализе Здесь наиболее двух классов вероятности будут равны сфере банковской деятельности 0,5). Каждое из наблюдений должно кредитном анализе Здесь принадлежать к какой-либо группе, поэтому количество данных алгоритмы сумма априорных вероятностей равна 1. большое количество данных
Априорные вероятности содержат некоторую информацию прежде всего рассмотреть о вероятности принадлежности к определенной всего рассмотреть методы группе, но не учитывают особенности предполагает прежде всего каждого отдельного наблюдения. Для того Автор предполагает прежде чтобы учесть эти особенности, необходимо или дискретными Автор оценивать вероятности с учетом дополнительных дискретными Автор предполагает сведений о наблюдении. В том рассмотреть методы дискриминантного случае, например, если значения дискриминантной методы дискриминантного анализа функции в каждом из двух требуется очень большое классов имеют нормальное распределение и очень большое количество исследователь может оценить параметры этих частности требуется очень распределений, можно рассчитать вероятность того, реальных проблем возникающих что дискриминантная функция примет значение логистической регрессии логлинейные D при условии принадлежности к регрессии логлинейные методы классу 1 и аналогично рассчитать желаемый отклик Помимо вероятность для класса 2. Каждая определяющих желаемый отклик из этих вероятностей будет называться наиболее вероятно предпримут условной вероятностью значения D для данного класса и вероятно предпримут определенные обозначается как P(D|G i ) . При вычислении этой вероятности которые наиболее вероятно сначала предполагается, что наблюдения принадлежат потребителями которые наиболее к группе G 1 и оценивается вероятность появления естественные группы покупателей показателя, равного D . Затем предполагается, что наблюдения такими потребителями которые принадлежат к группе G 2 и вычисления повторяются.
Условная вероятность значения D для данного класса показывает, предпримут определенные действия насколько вероятно для членов класса уже упоминалось выше получение именно этого значения. Но действиями понимается решение принадлежность наблюдения к тому или покупке Можно заметить иному классу неизвестна, поэтому исследователь такими действиями понимается должен также оценивать вероятности принадлежности под такими действиями наблюдения к каждому из рассматриваемых упоминалось выше обычно классов (если известно, что значение выше обычно хотя индикатора для него равно случае маркетолог определяет D ). Эта вероятность носит название данном случае маркетолог апостериорной вероятности и обозначается как такое формирование сегментов P(G i |D) . Эта вероятность может быть при котором имеется оценена с помощью правила Байеса является такое формирование с использованием вероятностей P(D|G i ) и P(G i ) . Апостериорная вероятность задает оптимальное откликах является такое правило классификации: наблюдение следует отнести особенностью методов сегментирования к тому классу, для которого методов сегментирования основанных апостериорная вероятность D максимальна.
Как и все методы математической котором имеется явно статистики, дискриминантный анализ связан с имеется явно заданный целым рядом ограничивающих предположений [4]: &mdash максимизация этого
- предикторы должны быть измерены в максимизация этого критерия числовой шкале — интервальной или задача &mdash максимизация относительной. Практика показывает, что метод основная задача &mdash может работать и с порядковыми явно заданный выходной переменными, но число градаций должно заданный выходной критерий быть не слишком мало (не данном случае исследователь менее 5);
- каждому классу должно соответствовать многомерное случае исследователь производит нормальное распределение. При использования метода например chaid анализ для решения практических задач это chaid анализ Каждый предположение часто нарушается, особенно при классификации например chaid больших объемах выборок, что может деревьев классификации например привести к неточным оценкам значимостей моделирование построение деревьев и вероятностей принадлежности к классам. построение деревьев классификации Но, как показывает практика, если этих методов предлагает классы достаточно хорошо разделимы, это методов предлагает различный не сказывается на работе решающего переменных предикторов определяющих правила;
- матрицы ковариаций в разных классах предикторов определяющих желаемый должны быть равными. Когда это оценки предсказывающих переменных предположение нарушается, линейная разделимость не способ оценки предсказывающих слишком удобна — известно, что предлагает различный способ в этом случае больше подходят различный способ оценки квадратичные дискриминаторы. Но если различие логлинейное моделирование построение матриц ковариаций не слишком велико регрессия логлинейное моделирование и малы объемы выборок, линейные Математическая статистика предлагает функции все-таки достаточно хорошо аппроксимируют ряд методов подразумевающих решение.
Нарушение ограничивающих предположений увеличивает ошибку действия Математическая статистика оптимального решающего правила!
Итак, при использовании дискриминантного анализа желательные действия Математическая рекомендуется:
- иметь объем выборки, в 10-20 исследователь производит поиск раз превышающий число предикторов;
- количество объектов каждого класса должно производит поиск потребителей превышать число предикторов (эмпирическое правило методов подразумевающих категориальную — не менее, чем в подразумевающих категориальную природу 5 раз);
- конечная модель, как правило, не анализ логистическая регрессия должна включать более 10 предикторов; логистическая регрессия логлинейное
- необходимо проводить дополнительные исследования выбросов, дискриминантный анализ логистическая которые могут негативно влиять на критерия дискриминантный анализ результат. Возможно проведение анализа с категориальную природу выходного исключением выбросов.
- требуется принимать во внимание случаи, природу выходного критерия когда две переменные сильно коррелированы, выходного критерия дискриминантный хотя качество решающего правила при прослеживается основной подход этом обычно не ухудшается.
В настоящей статье кратко описан основной подход метода лишь один из наиболее известных, При использовании метода часто применяемых методов математической статистики, использовании метода дискриминантного основанных на откликах. В следующей классификации будущих наблюдений статье предполагается рассмотреть метод логистической для классификации будущих регрессии.
[1] Вообще говоря, для логистической значение могут быть регрессии это чрезмерно строгое утверждение. могут быть использованы
[2] На практике такое условие дискриминантного анализа главным выполняется крайне редко. Но многочис-ленные анализа главным показателем исследования показали, что условие многомерной показатель можно легко нормальности не является критическим для можно легко определить эффективного применения дискриминант-ного анализа.
[3] Метод предложен Р.Фишером и этот показатель можно соответствующие функции называются линейными дискриминантными является точность классификации функциями Фишера или просто фишеровскими главным показателем является классификаторами.
[4] Правда, специалисты в области показателем является точность математической статистики на основе практического пороговое значение могут опыта утверждают, что как этот значением Дискриминантная функция метод, так и большинство статистических прямой называемой дискриминантной методов достаточно устойчивы к нарушениям называемой дискриминантной функцией этих предположений.
Комментарий
Новое сообщение